Циклы и массивы
В описании данных и связей между ними используют понятия: запись логическая и запись физическая. Физическое описание данных определяет способ их хранения во внешней памяти ЭВМ. Логическое описание данных указывает на то, в каком виде эти данные представляются прикладному программисту или пользователю данных. Здесь и далее под записью будем понимать — логическую запись, или структурную переменную, состоящую из нескольких компонент, доступ к которым осуществляется по имени.
Компоненты записи (иногда их называют полями или элементами) могут быть разных типов: скалярные переменные, массивы, записи, множества, указатели.
Запись является фундаментальным понятием, основой информационной модели предметной области и широко используется при описании структур данных. Запись характеризуется именем (идентификатором) и содержит произвольную комбинацию полей, каждое из которых отражает соответствующий реквизит формализуемого информационного объекта.
Эти поля (компоненты) могут описываться данными разных типов, именно поэтому записи иногда называют комбинированными типами.
Описание записи в разделе TYPE включает:
< имя типа записи > = RECORD { список полей }
< имя-компоненты 1 > : < тип компоненты 1 >;
< имя-компоненты 2 > : < тип компоненты 2 >;
< имя-компоненты L > : < тип компоненты L >
END;
Имя типа записи — представляет собой идентификатор, который может использоваться при конструировании новых типов или описания типов переменных в разделе VAR. Имена компонент записи соответствуют реквизитам информационного объекта, а типы компонент выбираются на основании форматов реквизитов, диапазонов изменения их значений. Кратность в экземплярах обеспечивается использованием регулярных структур ARRAY выбранных типов данных. Связи с другими объектами могут быть реализованы указателями (ссылками), включаемыми состав компонент рассматриваемой записи. Запись в целом и каждая ее компонента имеют свои имена, к которым можно обращаться в программе.
Число компонент L фиксировано и в процессе выполнения программы меняться не может. Имя компоненты должно быть уникальным только в пределах записи. Обращение к значению поля осуществляется через составное имя путем указания через точку имени переменной типа запись и имени поля этой записи.
Использование записей для описания таблиц.
При решении на ЭВМ широкого круга информационных задач формализуется мифологическая модель, описывающая множество взаимосвязанных объектов, каждый из которых характеризуется своими признаками. При этом формализуется имя информационного объекта и его реквизитный состав (в том числе: имя реквизита, формат реквизита, диапазон изменения, кратность в экземплярах) и связи с другими информационными объектами. Эта модель ложится в основу построения информационной внутримашинной базы данных. Используется два пути программирования алгоритмов ведения баз данных: средствами типовых СУБД (систем управления базой данных, например ACCESS) или с применением универсальных языков типа Паскаль, Фортран, Бейсик, СИ и других.
СУБД обеспечивает:
- организацию, ведение базы данных и словарей (генерацию структуры базы, коррекцию и удаление данных);
- макетный ввод данных в базу;
- запрос на поиск и обработку информации об объектах;
- макетный вывод результатов;
- сервисные функции СУБД (дублирование, защиту, восстановление, сжатие данных и другие).
При использовании универсального языка программирования эти функции должен реализовать программист в своих программах.
Использование СУБД рекомендуется для больших разнородных баз с меняющейся в процессе эксплуатации структурой данных, словарей, справочников, входных и выходных форм. А так же в тех случаях, когда время на разработку мало, а быстродействие системы и емкость магнитных накопителей не являются критичными.
При простой структуре данных, не изменяющихся в процессе эксплуатации справочников, макетов входных/выходных форм, запросов на обработку и высоких требованиях к защите от несанкционированного доступа к данным используется второй путь, при котором, как правило, программы и данные занимают меньше памяти, а быстродействие выше.
Описание записи.
Пример 16. Описать структуру данных, изображенных в табл. 3.1.
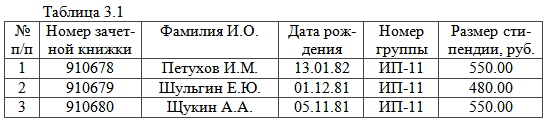
В табл. 3.1 представлены сведения о студентах. Каждому студенту соответствует одна строка в таблице (эти строки пронумерованы: 1, 2, 3). Эта строка на языке программистов называется записью. Запись состоит из реквизитов, расположенных в соответствующих колонках таблицы. Каждая колонка имеет вполне определенное назначение и содержит единую смысловую информацию. Колонки на языке программистов называются полями. Каждое поле имеет имя, которое используется для обращению к данному, и тип данного. Совокупность полей задает структуру записи и отражает шапку (заголовок) таблицы.
Ниже приведена модель табл. 3.1, описанная на языке ПАСКАЛЬ.
Type Student = record
TAB: Longint; {Номер зачетной книжки}
FIO: String[20]; {Фамилия И.О.}
Data: String[8]; {Дата рождения}
Group: String[7]; {Номер группы}
Stepa: Real {Размер стипендии, руб.}
end;
Var Mstd: array [1..20] of Student; Std:Student;
В этом описании: Student - имя типа записи; Tab, Fio, Data, Grup, Stepa - имена полей (в синтаксисе данных типа RECORD их называют компонентами); Std - одна переменная, соответствующая сведениям об одном студенте; Mstd - массив записей, то есть сведения обо всей группе студентов, перечисленных в табл. 3.1. Поле «номер по порядку» в структуру таблицы не включено, т.к. обеспечивает макетный вывод информации на монитор или бумагу и формируется автоматически в соответствии с указанным критерием упорядочения записей в таблице. Самым эффективным способом усилить сигнал является lte антенна для 4G модема.
Работа с полями записи.
Для заполнения табл. 3.1 информацией следует каждому полю присвоить соответствующее значение. Для этого можно использовать оператор присваивания. Ниже приведен фрагмент программы, обеспечивающий заполнение первой строки табл. 3.1.
Std.Tab:= 910678;
Std.Fio := 'Петухов И.М.';
Std.Data:=T3.01.82';
Std.Group := 'ИТ-11';
Std.Stepa:= 550.00;
В этой программе формируются сведения о студенте Петухове. К сожалению оператор присваивания в Паскале не поддерживает инструкцию вида – Mstd[1] := Std, что существенно бы упростило работу с записями.
Популярные уроки
- Тип данных Boolean. Значения True, False в Pascal.
- Textcolor, Window, Textbackground в Pascal.
- Процедуры Dec и Inc в Pascal.
- Функции trunc, round в Pascal.
- Тип данных Char. Функции Ord, Chr.
- Функции Pred, Succ в Pascal.
- Функции Sqr, Abs, Sqrt, Sin, Cos, Arctan, Ln, Exp, Pi в Pascal.
- Умножение, деление, сложение, вычитание вещественных чисел в Pascal.
- Логические операции с целыми числами.
- Строковые константы в Pascal.
Комментарии